AI in e-health: een interview
In de wereld van e-health is Artificial Intelligence (AI) een trendy topic. Google heeft interesse. Watson, de supercomputer van IBM, houdt zich ermee bezig. En verder worden er talloze speculatieve artikelen geschreven over hoe AI de zorgsector zal gaan veranderen. Vaak blijft het echter onduidelijk wat dit in de praktijk nou precies inhoudt.
Om een tipje van de sluier te lichten over hoe AI ingezet kan worden en wat het kan betekenen voor e-health oplossingen, stel ik in deze blog een paar vragen aan een van onze AI-experts, Lydia Mennes. In december rondde ze enkele AI-projecten, gesubsidieerd door Mkb-innovatiestimulering Regio en Topsectoren (MIT), af.
Het inzetten van Artificial Intelligence of Machine Learning klinkt al snel alsof het iets magisch is wat computers doen. Kan je een beeld schetsen van wat je ongeveer doet wanneer je met AI werkt?
Er komt natuurlijk een heleboel bij kijken, maar het basisidee is dat je een ‘model’ wilt trainen op een bepaalde taak. Een bekend voorbeeld is een model van Google dat getraind is om katten in plaatjes te kunnen herkennen.
Er zijn verschillende methodes om een model te trainen, en een daarvan is om het model duidelijke instructies mee te geven. Dus dat je bijvoorbeeld zegt: “Op dit plaatje staat een kat”. Dit herhaal je dan een heleboel keer, en dan moet het model uiteindelijk met die kennis katten kunnen herkennen in plaatjes die het nog niet eerder gezien heeft. Deze aanpak noem je trainen ‘met supervisie’.
Je kan het ook zonder supervisie doen. In dat geval geef je een model een heleboel data en laat je het zelf patronen herkennen. Dat is hoe Google het gedaan heeft met de kattenplaatjes. Ze gaven het model een grote dataset van verschillende plaatjes die ze op YouTube hadden gevonden, en uiteindelijk kwam het katten-patroon eruit rollen als een van de patronen die het model heel duidelijk kon herkennen.
Ok. Dus voor CTcue train je ook modellen die een bepaald patroon kunnen herkennen. Kan je enkele voorbeelden geven en vertellen waar ze voor gebruikt worden?
Bij CTcue train ik modellen op het juist kunnen interpreteren van vrije teksten in het EPD, zoals rapportages en brieven. De teksten bevatten namelijk veel onduidelijkheden. Denk aan zinnen als: “Patiënt heeft mogelijk een infectie” of “De vader van de patiënt heeft een hartinfarct gehad”. Als een gebruiker op alle patiënten met een infectie of een hartinfarct zoekt, dan moet onze zoekmachine duidelijk kunnen herkennen welke patiënten echt een infectie of infarct hebben gehad, en bij welke het om een hypothetische situatie of een familielid gaat. Hier heb ik nu modellen voor.
Verder werk ik ook aan een project als Timeline Extraction. Dit heeft als doel om in teksten te kunnen herkennen wanneer iets heeft plaatsgevonden. Als er in een document staat “Patiënt heeft vorig jaar een hartinfarct gehad”, en de brief dateert van 2017, dan moet deze patiënt niet als resultaat naar boven komen als een gebruiker zoekt op alle patiënten met een hartinfarct in 2017.
In het project Measurement Extraction heb ik een methode ontwikkeld waarmee metingen en labwaarden uit een tekst gehaald kunnen worden[1]. En met Medical Concept Detection wil ik in teksten precies kunnen identificeren welke medische concepten, zoals diagnoses, verrichtingen en anatomische concepten, er in staan.
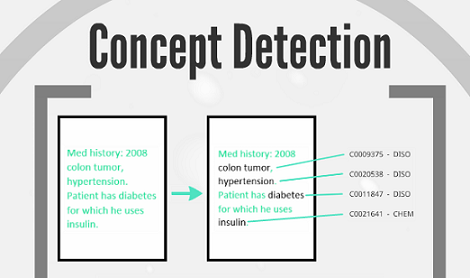
Een plaatje uit Lydia’s presentatie. Het laat zien hoe medische concepten in een tekstdocument herkend en gelinkt worden met de kennis uit een database. ‘Hypertension’ wordt bijv. als ‘Disorder’ herkend en ‘insuline’ als een ‘Chemical’.
Ik kan me voorstellen dat er veel onderzoek wordt gedaan naar het interpreteren van (medische) teksten. Kan je gebruik maken van al bestaande modellen?
Het klopt dat er veel onderzoek wordt gedaan naar het extraheren van informatie en ook naar het interpreteren van medische data. En ik kan ook zeker goed gebruik maken van de kennis die er al is. Maar wat je natuurlijk veel ziet is dat (open-source) modellen voornamelijk getraind zijn op Engelse teksten. Daar kom je dus niet zo ver mee. Nederland is een te klein taalgebied.
Daarnaast is Nederlands niet de gemakkelijkste taal voor het extraheren van informatie. Wij plakken namelijk een heleboel woorden aan elkaar, waardoor ze lastig te herkennen zijn. Waar “elleboog” en “punctie” bijvoorbeeld los van elkaar perfect herkend zouden worden, wordt in een tekst “elleboogpunctie” geschreven, en dat is dan weer niet te herkennen. Dat is lastig, want zo loop je snel veel woorden mis.
Zijn er bepaalde uitdagingen of dingen waar je tegenaan loopt?
Wat nu nog een uitdaging is om ook gebruik te kunnen maken van de context in teksten. Dus als er bijvoorbeeld ergens staat “[X] is voorgeschreven in december”, dat je dan kan herkennen dat ‘X’ een medicijn is. De context kan een extra hulpmiddel zijn om teksten te interpreteren, want je kan op die manier makkelijker rekening houden met onbekende afkortingen of alternatieve benamingen die dokters gebruiken.
Een andere uitdaging is het herkennen van relaties tussen verschillende documenten. Dus als een patiënt in een brief in mei een bepaald medicijn krijgt voorgeschreven, en dat er in een brief van juni staat dat er bijwerkingen zijn. Het zou mooi zijn als we deze relaties tussen documenten ook kunnen vastleggen, zodat een gebruiker ook goed geïnformeerd kan worden over de ontwikkelingen die een patiënt maakt.
Waar wil je uiteindelijk naar toewerken?
Nu is het nog zo dat we met elk project één probleem aanpakken. Je traint een model op dat ene probleem, maar dat betekent dat je dus meerdere modellen moet trainen en dat je de data door elk model moet sturen. Dat is een kostbaar proces. Graag wil ik gebruik gaan maken van wat ze een Deep Neural Network noemen. Dat is wat Google ook gebruikt heeft voor het herkennen van katten in plaatjes. Met een Deep Neural Network wordt het mogelijk om de problemen die we nu afzonderlijk aanpakken in één keer aan te pakken. Dan hou je uiteindelijk dus één efficiënt ‘supermodel’ over.